The main goal of this lesson is to demonstrate the importance of data visualization and how it can unlock a variety of learning and research pathways—ranging from exploratory data analysis and statistical inference to understanding machine learning processes and data storytelling.
If you’re looking for ways to approximately predict specific values based on a given dataset for data storytelling, or if you’ve ever wondered how machine learning models that predict values (rather than categories) work, this lesson is for you. It will introduce you to the concept of statistical inference—a mathematical calculation used in predictive machine learning algorithms—through various data visualization techniques. These visualization methods will also enhance your data storytelling skills, not only in describing existing data but also in predicting values based on the available data.
Data visualization is central to this lesson, serving as both the means and the goal. You’ll not only learn to write Python code and engage in hands-on data visualization, but also discover how to explore, understand, and predict dataset values through visualization techniques.
How is this lesson structured?
The lesson begins with a brief overview of various graph types and their applications.
Next, you’ll explore statistical inference and linear regression, which will help you understand correlations and make predictions based on datasets. These concepts also provide foundational insights into how machine learning models work.
Finally, you’ll learn how to use visualization techniques to identify patterns within a dataset and extract statistical insights, bringing together the concepts from the previous sections and engaging in hands-on data visualization in Python.
What background knowledge do you need for this lesson?
Basic acquaintance with Python
Basic mathematical background
Curiosity to learn more about Python programming, statistics and data storytelling
Why Visualize Data?
Data visualization has multiple purposes. It can help you understand trends and correlations in a dataset. It can also help you introduce a dataset to others in scientific texts or in data storytelling.
Graph Categories
Most graphs used for data visualization fall into one of the following four general categories, based on their function. In this lesson, we won’t cover how to create all of these graphs in Python, but will focus on a few that are useful for statistical inference and data storytelling with our specific dataset. However, it’s helpful to know the names of these graphs and understand the contexts in which they can be applied.
Explore Relationships between two or more Features
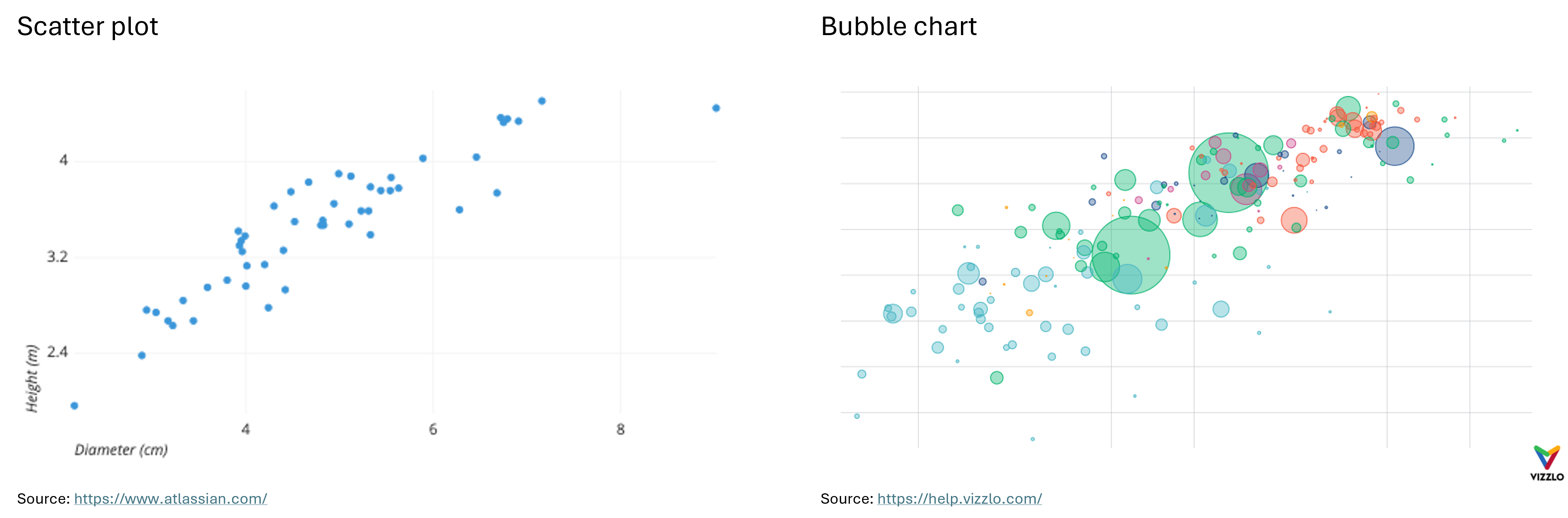
Scatter Plot: “A scatter plot (aka scatter chart, scatter graph) uses dots to represent values for two different numeric variables. The position of each dot on the horizontal and vertical axis indicates values for an individual data point. Scatter plots are used to observe relationships between variables.” (Atlassian) For example, the X-axis can represent the age of the employees at a company, where the Y-axis represents their income.
Bubble Chart: “A bubble chart (aka bubble plot) is an extension of the scatter plot used to look at relationships between three numeric variables. Each dot in a bubble chart corresponds with a single data point, and the variables’ values for each point are indicated by horizontal position, vertical position, and dot size.” (Atlassian) In addition to representing three numerical features with their X and Y values and bubble size, a bubble chart can also represent a categorical feature through color. For example, if the X-axis represents the age of employees at a company, the Y-axis represents their income, and the size of the bubbles represents their years of work experience, the color of the bubbles can indicate their gender.
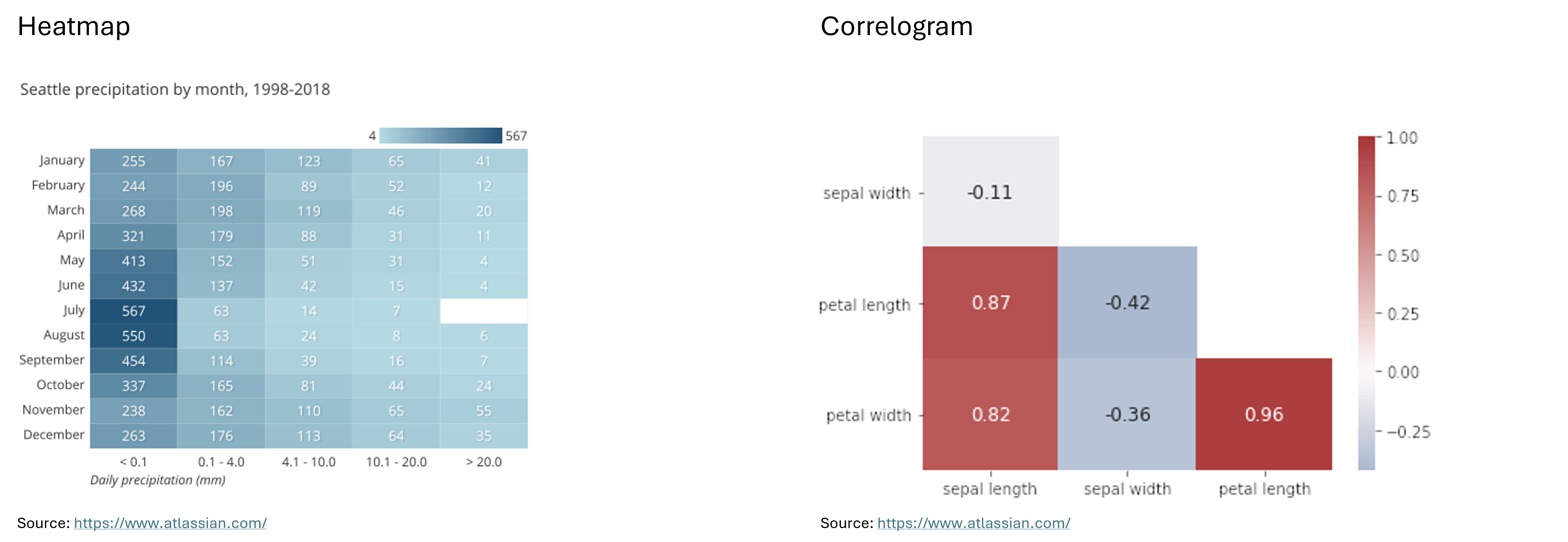
Heatmap: “A heatmap (aka heat map) depicts values for a main variable of interest across two axis variables as a grid of colored squares. The axis variables are divided into ranges like a bar chart or histogram, and each cell’s color indicates the value of the main variable in the corresponding cell range.” (Atlassian)
Correlogram: “A correlogram is a variant of the heatmap that replaces each of the variables on the two axes with a list of numeric variables in the dataset. Each cell depicts the relationship between the intersecting variables, such as a linear correlation. Sometimes, these simple correlations are replaced with more complex representations of relationship, like scatter plots. Correlograms are often seen in an exploratory role, helping analysts understand relationships between variables in service of building descriptive or predictive statistical models.” (Atlassian) For example, a correlogram can reveal the correlations between features such as the sepal width, petal length, and petal width of an iris, showing how closely these attributes are related to each other.
Below you can see examples of a scatter plot, a bubble chart, a heatmap and a correlogram:
Compare Different Measures or Trends
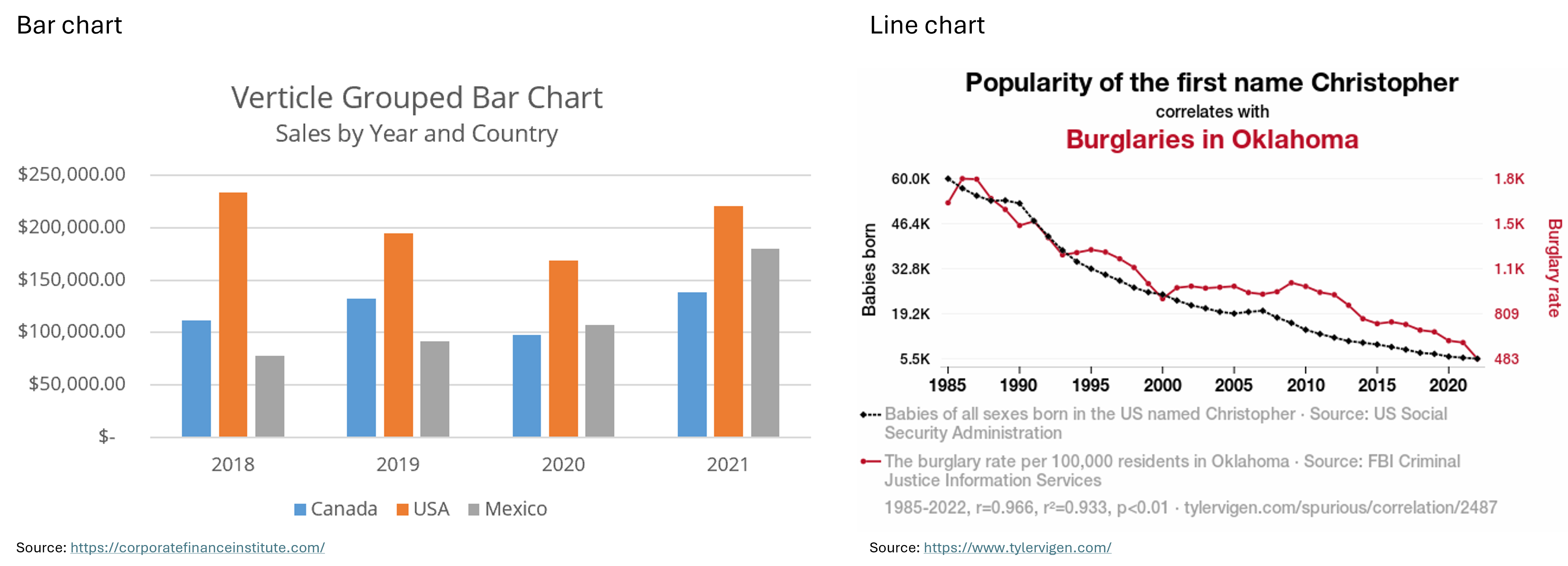
Bar Chart: “A bar chart (aka bar graph, column chart) plots numeric values for levels of a categorical feature as bars. Levels are plotted on one chart axis, and values are plotted on the other axis. Each categorical value claims one bar, and the length of each bar corresponds to the bar’s value. Bars are plotted on a common baseline to allow for easy comparison of values.” (Atlassian) For example, the X-axis could represent the skill levels of employees at a company (entry-level, mid-level, and advanced), while the Y-axis shows the average annual salary for each group.
Line Chart: “A line chart (aka line plot, line graph) uses points connected by line segments from left to right to demonstrate changes in value. The horizontal axis depicts a continuous progression, often that of time, while the vertical axis reports values for a metric of interest across that progression.” (Atlassian) For example, the X-axis could represent the years from 2000 to 2024, while the Y-axis shows the average salary of advanced employees at two different companies over this time period.
Below you can see examples of a bar chart and a line chart.
Explore Distributions
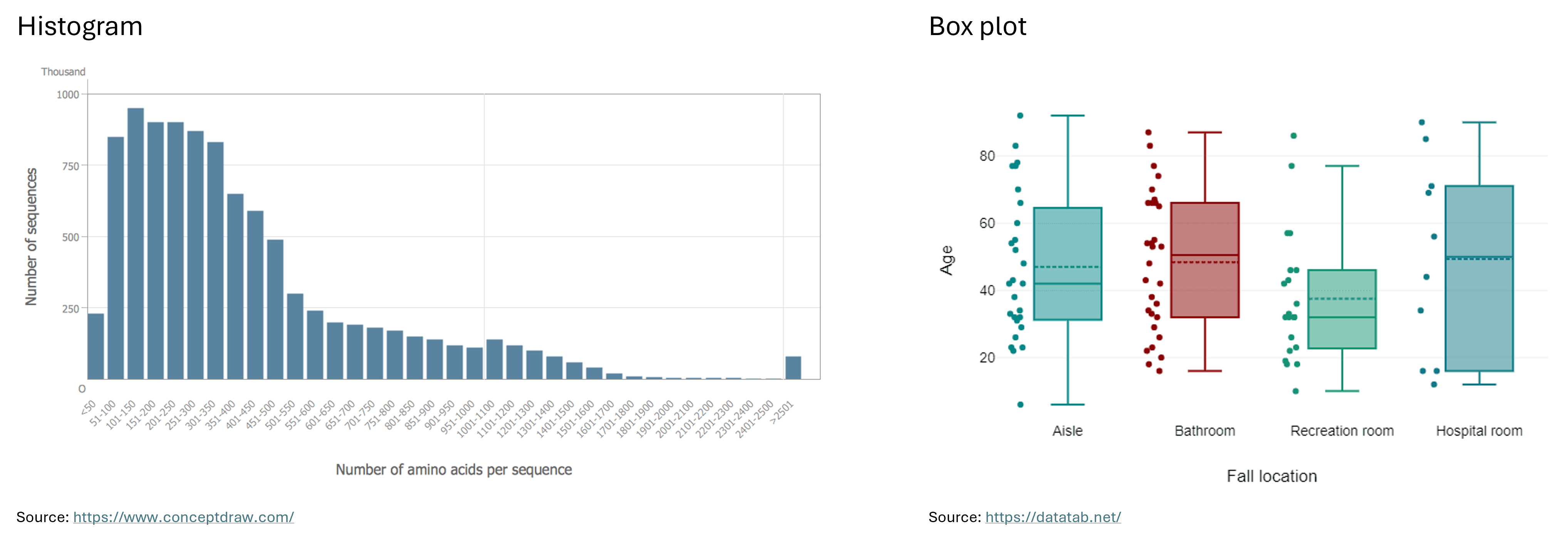
Histogram: “A histogram is a chart that plots the distribution of a numeric variable’s values as a series of bars. Each bar typically covers a range of numeric values called a bin or class; a bar’s height indicates the frequency of data points with a value within the corresponding bin.” (Atlassian) For example, the bins on the X-axis could represent salary ranges such as ¥30,000 - ¥39,999, ¥40,000 - ¥49,999, and ¥50,000 - ¥59,999, with the Y-axis showing the number of Japanese employees in each salary range.
Box Plot: “Box plots are used to show distributions of numeric data values, especially when you want to compare them between multiple groups. They are built to provide high-level information at a glance, offering general information about a group of data’s symmetry, skew, variance, and outliers. It is easy to see where the main bulk of the data is, and make that comparison between different groups.” (Atlassian)
“The box itself indicates the range in which the middle 50% of all values lie. Thus, the lower end of the box is the 1st quartile and the upper end is the 3rd quartile. Therefore below Q1 lie 25% of the data and above Q3 lie 25% of the data, in the box itself lie 50% of your data. Let’s say we look at the age of individuals in a boxplot, and Q1 is 31 years, then it means that 25% of the participants are younger than 31 years. If Q3 is 63 years, then it means that 25% of the participants are older than 63 years, 50% of the participants are therefore between 31 and 63 years old. Thus, between Q1 and Q3 is the interquartile range.
In the boxplot, the solid line indicates the median and the dashed line indicates the mean. For example, if the median is 42, this means that half of the participants are younger than 42 and the other half are older than 42. The median thus divides the individuals into two equal groups.
The T-shaped whiskers go to the last point, which is still within 1.5 times the interquartile range. The T-shaped whisker is either the maximum value of your data but at most 1.5 times the interquartile range. Any observations that are more than 1.5 interquartile range (IQR) below Q1 or more than 1.5 IQR above Q3 are considered outliers. If there are no outliers, the whisker is the maximum value.” (DATAtab)
Draw Comparisons
Pie Chart: “A pie chart shows how a total amount is divided between levels of a categorical variable as a circle divided into radial slices. Each categorical value corresponds with a single slice of the circle, and the size of each slice (both in area and arc length) indicates what proportion of the whole each category level takes.” (Atlassian) For example, a pie chart could show the percentage of a company’s budget allocated to different task areas.
Stacked Bar Chart: “A stacked bar chart is a type of bar chart that portrays the compositions and comparisons of several variables through time. Stacked charts usually represent a series of bars or columns stacked on top of one another. They are widely used to effectively portray comparisons of total values across several categories.” (Jaspersoft) For example, the X-axis of a stacked bar chart could represent bins, each covering a 5-year interval, while the Y-axis shows the number of employees at a company in each interval. Each bar can be divided into groups based on experience level, with different colors representing each group.
There are many other types of graphs beyond the ones introduced here, such as area charts, tree maps, funnel charts, violin plots, and more. To explore these charts and graphs further, visit the websites Atlassian or Storytelling with Data.
In the next section, we’ll take a closer look at the correlographic heatmap, the scatter plot, and the bubble chart. We’ll learn how to create them in Python and explore how they can contribute to statistical inference and data storytelling. To start, let’s first introduce the concept of statistical inference.
What is Statistical Inference?
📊 Inferential statistics, along with descriptive ststistics, are two major methods of statistical analysis.
Descriptive statistics summarizes and explains the data we already have, without making generalizations about a larger population.
In contrast, inferential statistics allows us to draw conclusions about an entire population or predict future trends through hypotheses. These hypotheses are formed based on observations and analysis of a sample from the population. The next step is to test whether the hypothesis is true and applicable to the broader population, or whether our observations were simply due to chance, making the hypothesis false.
🎓The online Encyclopedia of Mathematics provides the following, more detailed, definition of statistical inference:
“At the heart of statistics lie the ideas of statistical inference. Methods of statistical inference enable the investigator to argue from the particular observations in a sample to the general case. In contrast to logical deductions made from the general case to the specific case, a statistical inference can sometimes be incorrect. Nevertheless, one of the great intellectual advances of the twentieth century is the realization that strong scientific evidence can be developed on the basis of many, highly variable, observations.
The subject of statistical inference extends well beyond statistics’ historical purposes of describing and displaying data. It deals with collecting informative data, interpreting these data, and drawing conclusions. Statistical inference includes all processes of acquiring knowledge that involve fact finding through the collection and examination of data. These processes are as diverse as opinion polls, agricultural field trials, clinical trials of new medicines, and the studying of properties of exotic new materials. As a consequence, statistical inference has permeated all fields of human endeavor in which the evaluation of information must be grounded in data-based evidence.
A few characteristics are common to all studies involving fact finding through the collection and interpretation of data. First, in order to acquire new knowledge, relevant data must be collected. Second, some variability is unavoidable even when observations are made under the same or very similar conditions. The third, which sets the stage for statistical inference, is that access to a complete set of data is either not feasible from a practical standpoint or is physically impossible to obtain.” (Encyclopedia of Mathematics)
📈 When using methods of statistical inference, we work with samples of data because we don’t have access to the entire population. We observe and measure patterns and categories within these samples to form a hypothesis. Proving or rejecting the hypothesis requires mathematical methods that go beyond the scope of this lesson. If you’re interested in learning more about hypothesis testing, you can watch the YouTube video on this topic by DATAtab.
Correlation and Regression in Inferential Statistics
To perform inferential statistical analysis, it’s important to identify correlations between features in the data. If two numerical features are correlated, an increase or decrease in one tends to coincide with an increase or decrease in the other. For example, if we have data on the lifestyle habits of a group of people and their age at death, we can look for lifestyle factors (such as the frequency of physical exercise or eating habits) that may correlate with longevity and a higher age at death.
If such a correlation is observed and measured, we can use it to predict the lifespan of individuals whose data is not part of the sample. To make this prediction, we first need to establish a mathematical or numerical relationship between lifespan and the other features in the dataset that may correlate with it. In this case, lifespan is considered the dependent variable, as its value depends on the other features. The other features, in turn, are considered independent variables, as their values do not depend on lifespan. This process of numerically relating a dependent variable to independent variables is called regression.
💡 Note: Correlation is not causation! In the example above, even if a correlation is found between lifestyle and lifespan, scientists must seek clinical evidence to determine whether there is also a causal relationship between these two factors. Tyler Vigen, author of the book Spurious Correlations, created a website where he shares humorous correlations between unrelated trends to emphasize this important point: correlation does not imply causation.
🔮 However, correlations can still be useful for predicting future trends through regression methods, even if they don’t explain the underlying reasons for these trends.
Data Visualization and Statistical Inference
In the previous chapters, we explored ten types of graphs and their use cases, as well as the concepts of correlation and regression in the context of inferential statistics. Now, it’s time to put this knowledge into practice! In this chapter, we’ll work with the Income and Happiness Correlation dataset from Kaggle, which consists of 111 data points. We’ll visualize this dataset and learn how to perform inferential statistical analysis on it.
💡 Before visualizing any dataset, it’s important to answer the following questions:
What kind of data is stored in the dataset?
What are the dimensions of the dataset?
Why do I want to visualize the dataset? What information do I hope to gain through visualization? And which type of graph best represents the information I’m looking for?
Let’s answer these questions for our dataset by writing some code.
Exploring the Dataset
The dataset we’re working with is stored in a CSV (comma-separated values) file on GitHub. Let’s load it into our notebook and store it in a pandas DataFrame called happy_df:
import pandas as pd# path to the dataset: url="https://raw.githubusercontent.com/HERMES-DKZ/data_challenges_data_carpentries/main/\data_carpentries/statistical_inferece_data_visualization/data_statistical_inference_data_visualization/income_happiness_correlation.csv"# loading the dataset and storing it in a pandas DataFrame:happy_df= pd.read_csv(url)# displaying the first five rows of the DataFrame: happy_df.head()
country
adjusted_satisfaction
avg_satisfaction
std_satisfaction
avg_income
median_income
income_inequality
region
happyScore
GDP
country.1
0
Armenia
37.0
4.9
2.42
2096.76
1731.506667
31.445556
'Central and Eastern Europe'
4.350
0.76821
Armenia
1
Angola
26.0
4.3
3.19
1448.88
1044.240000
42.720000
'Sub-Saharan Africa'
4.033
0.75778
Angola
2
Argentina
60.0
7.1
1.91
7101.12
5109.400000
45.475556
'Latin America and Caribbean'
6.574
1.05351
Argentina
3
Austria
59.0
7.2
2.11
19457.04
16879.620000
30.296250
'Western Europe'
7.200
1.33723
Austria
4
Australia
65.0
7.6
1.80
19917.00
15846.060000
35.285000
'Australia and New Zealand'
7.284
1.33358
Australia
🔍 Take a moment to examine the first five rows of the DataFrame. What types of values do you see in each column? Which columns contain numerical values, and which contain categorical values? What information does the dataset include, and what information might be missing?
Run the following line of code to gain more information about the structure of happy_df:
# displaying information about the DataFrame:happy_df.info()
❓ Now that you know the dataset better, you can answer the question: what information can be inferred from this dataset? Which column contains values that could be dependent on other features, and thereby correlates with them? Would it be possible to predict the values of this column, given the values of one or more other columns in the dataset?
💡 Intuitively, one might assume that the happyScore column contains values that could be predicted based on the other features. So, it may be possible to estimate the average happiness score of a country’s population if we know its region, GDP, income inequality, and average income. In other words, there might be a correlation between happyScore and the other features.
But how can we determine with greater confidence that such a correlation exists, and identify which features are more strongly correlated with happyScore than others? Data visualization can help us answer these questions.
Drawing Heatmaps
One of the best and easiest ways to visualize correlations is through correlographic heatmaps. However, heatmaps can only show how changes in one numerical value are correlated with changes in another numerical value. Therefore, to create a heatmap of all numerical features that could be correlated with happyScore, we need to exclude the columns in happy_df that contain non-numerical values:
# selecting only the columns whose values are not of type 'object' and storing them in a new DataFrame:numerical_df= happy_df.select_dtypes(exclude=['object'])# displaying the first five rows of the new DataFrame:numerical_df.head()
adjusted_satisfaction
avg_satisfaction
std_satisfaction
avg_income
median_income
income_inequality
happyScore
GDP
0
37.0
4.9
2.42
2096.76
1731.506667
31.445556
4.350
0.76821
1
26.0
4.3
3.19
1448.88
1044.240000
42.720000
4.033
0.75778
2
60.0
7.1
1.91
7101.12
5109.400000
45.475556
6.574
1.05351
3
59.0
7.2
2.11
19457.04
16879.620000
30.296250
7.200
1.33723
4
65.0
7.6
1.80
19917.00
15846.060000
35.285000
7.284
1.33358
Now, let’s use the Python library Seaborn to create a heatmap of all the values in numerical_df:
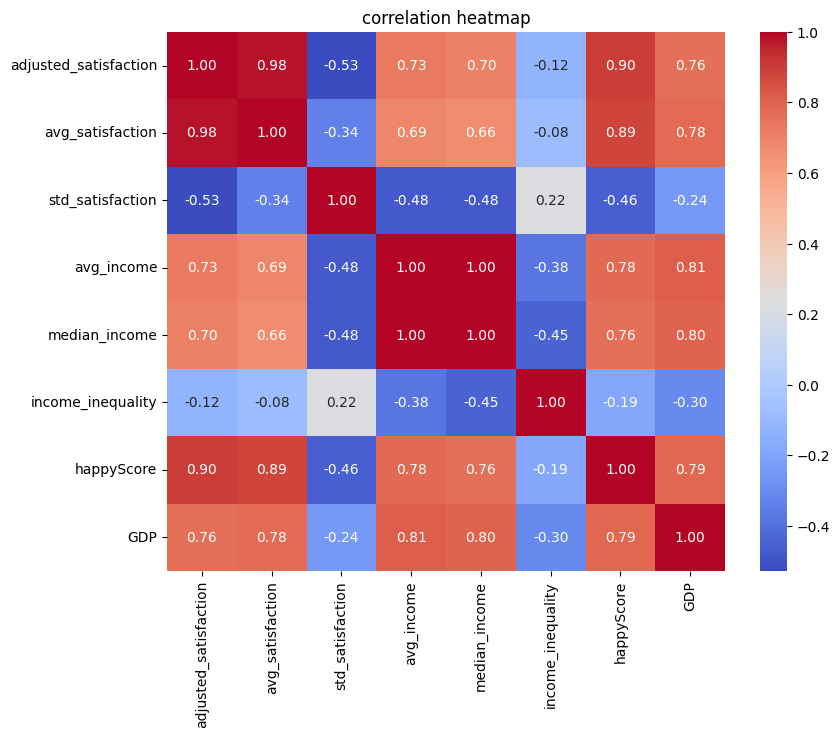
import matplotlib.pyplot as pltimport seaborn as sns# creating a matrix that contains the correlation of every feature in the DataFrame with every other feature:corr= numerical_df.corr(method='pearson')# defining the size of the graph: plt.figure(figsize=(9, 7))# generating a heatmap of the corr matrix, using the seaborn library:sns.heatmap(corr, annot=True, fmt=".2f", cmap='coolwarm', cbar=True)# giving the graph a title:plt.title('correlation heatmap')# diyplaying the graph: plt.show()
📝 In the code above, we’ve set cmap='coolwarm'. This means we want the heatmap to distinguish between negative and positive correlations using red and blue colors. More saturated shades of blue or red indicate stronger negative or positive correlation values
We’ve set annot=True in our code, which means we want the correlation coefficients to be displayed on the heatmap. The correlation coefficients are calculated using the Pearson method in corr= numerical_df.corr(method='pearson'). “The Pearson correlation measures the strength of the linear relationship between two variables. It has a value between -1 to +1, with a value of -1 meaning a total negative linear correlation, 0 being no correlation, and +1 meaning a total positive correlation.” (ScienceDirect)
📖 Here’s how to read and interpret the heatmap:
Darker red colors, accompanied by values closer to +1, indicate stronger positive correlations. This means that as one value increases at a certain rate, the other increases at a similar rate.
Darker blue colors, accompanied by values closer to -1, indicate stronger negative correlations. This means that as one value increases at a certain rate, the other decreases at a similar rate.
💡 By studying the heatmap above, we can observe the following patterns:
Each feature is most strongly correlated with itself, with a correlation coefficient of +1.
Values derived from the same feature demonstrate a high correlation. For example, the correlation coefficient between avg_satisfaction and adjusted_satisfaction is +0.98, because both stem from the satisfaction degree. The same is true about avg_income and median_income with the correlation coefficient being +1.
To create a more precise graph without redundant information, let’s retain only one column from the DataFrame that contains data on satisfaction or income, and remove the others:
# dropping a list of columns from numerical_df and storing the result in a new DataFrame:reduced_numerical_df= numerical_df.drop(['adjusted_satisfaction', 'std_satisfaction', 'median_income'], axis=1)reduced_numerical_df.head()
avg_satisfaction
avg_income
income_inequality
happyScore
GDP
0
4.9
2096.76
31.445556
4.350
0.76821
1
4.3
1448.88
42.720000
4.033
0.75778
2
7.1
7101.12
45.475556
6.574
1.05351
3
7.2
19457.04
30.296250
7.200
1.33723
4
7.6
19917.00
35.285000
7.284
1.33358
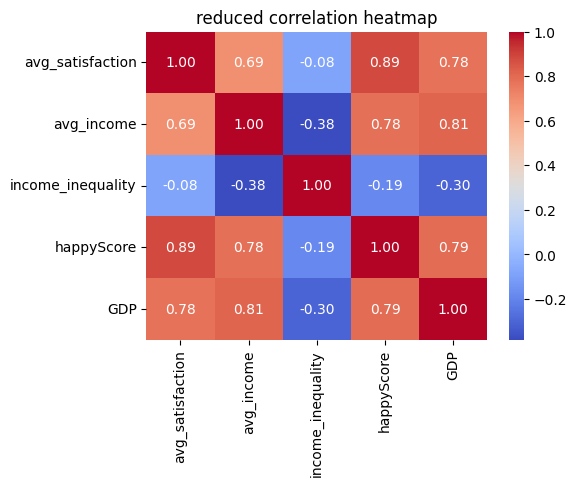
Let’s create the heatmap again, this time using reduced_numerical_df insted of numerical_df:
💡 This heatmap is more meaninful than the previous one and reveals more insights:
avg_satisfaction and avg_income have a correlation greater that +0.5, indicating that higher income is correlated with greater life satisfaction.
There is a strong positive correlation between avg_satisfaction and happyScore.
avg_satisfaction shows a positive correlation with GDP.
There is a positive correlation between avg_income and happyScore.
There is a positive correlation between avg_income and GDP.
The slight negative correlation between avg_income and income_inequality is also interesting: as the average income in a country increases, income inequality tends to decrease.
There is a negative correlation between GDP and income_inequality: higher GDP in a country is associated with lower income inequality.
Let’s take a closer look at the correlations we’ve observed between the happyScore and the other features by drawing different graphs.
Drawing Scatter Plots
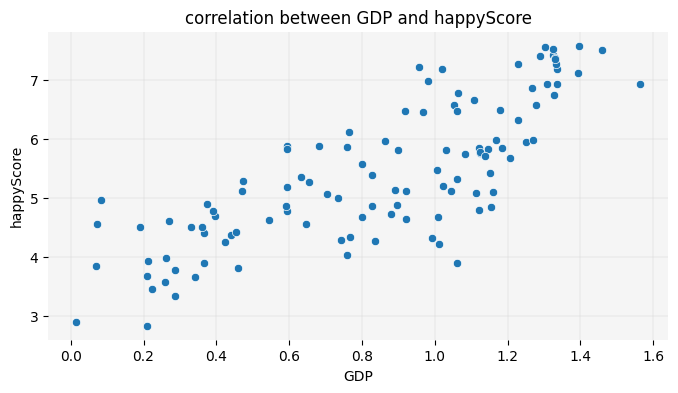
Now that we have a general understanding of the correlations within the happy_df dataset, let’s take a closer look at these relationships. We’ll start by visualizing the correlation between happyScore and another variable with a strong positive correlation, such as GDP. To achieve this, we can create a scatter plot:
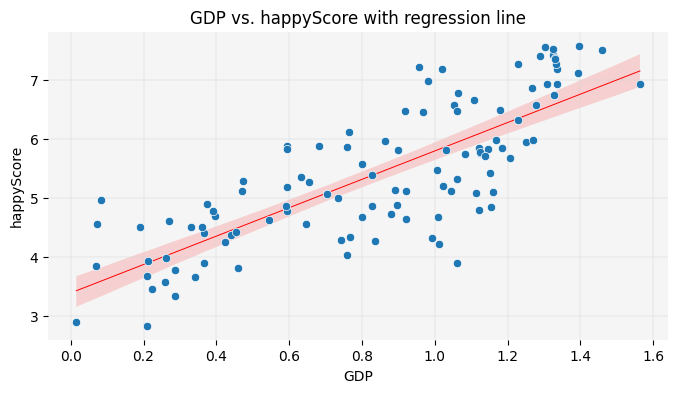
# defining the size of the graph: plt.figure(figsize=(8, 4))# creating a scatte plot, using the seaborn library:sns.scatterplot(data=happy_df, x='GDP', y='happyScore', zorder=3)"""The following block of code enhances the visual appeal of the graph:"""# adding grid to the plot:plt.grid(True, zorder=0, color='lightgray', linestyle='-', linewidth=0.3)# removing all spines (edges):sns.despine(left=True, bottom=True)# setting the background color:plt.gca().set_facecolor('whitesmoke')"""End of customization """# giving the graph a title:plt.title('correlation between GDP and happyScore')# diyplaying the graph: plt.show()
🤓 Fun fact: You are now one step away from understanding how machine learning models predict values. Such a model calculates relationships between features, as shown above, and fits a line to represent them. This involves drawing a line on the scatter plot so that the sum of the squared distances from each point to the line is minimized. This line, as you learned in the previous chapter, is called a regression line. The method used to calculate the line’s position is known as linear regression in statistics. Here is the code to display the regression line on the graph:
plt.figure(figsize=(8, 4))sns.scatterplot(data=happy_df, x='GDP', y='happyScore', zorder=3)plt.grid(True, zorder=0, color='lightgray', linestyle='-', linewidth=0.3)sns.despine(left=True, bottom=True)plt.gca().set_facecolor('whitesmoke')# adding a regression line to the graph:sns.regplot(data=happy_df, x='GDP', y='happyScore', scatter=False, color='red', line_kws={'zorder': 2, 'linewidth': 0.7})plt.title('GDP vs. happyScore with regression line')plt.show()
🤓 End of fun fact!
The scatter plot reconfirms the insights we gained from the heatmap, visually demonstrating the positive correlation between GDP and happyScore: as the value of GDP on the X-axis increases, the happyScore on the Y-axis also tends to increase.
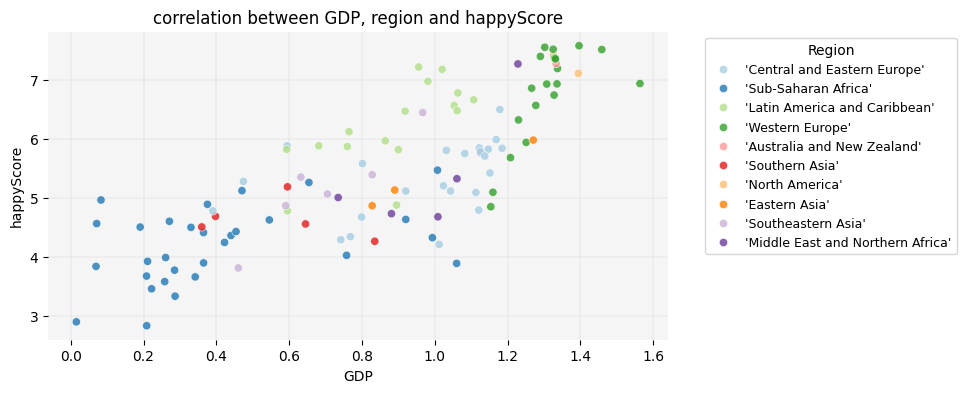
What if we also wanted to visualize the region of each country represented by a dot in the scatter plot? Unlike the heatmap, which couldn’t display regions due to their categorical nature, the scatter plot allows us to assign a unique color to each region. This way, we can see which regions tend to have the highest GDP and happyScore values:
plt.figure(figsize=(8, 4))# adding region to the graph as hue:sns.scatterplot(data=happy_df, x='GDP', y='happyScore', hue='region', palette='Paired', alpha=0.8, zorder=3)plt.grid(True, zorder=0, color='lightgray', linestyle='-', linewidth=0.3)sns.despine(left=True, bottom=True)plt.gca().set_facecolor('whitesmoke')# adding a legend to the graph:plt.legend(title='Region', title_fontsize='10', fontsize='9', bbox_to_anchor=(1.05, 1), loc='upper left')plt.title('correlation between GDP, region and happyScore')plt.show()
💡 Interesting! Here are some observable trends in the graph:
Sub-Saharan African countries have the lowest GDPs, whereas Western European and North American countries have the highest. However, there are countries in the former region in which the happyScore is as high as in some Western European countries, regardless of their very low GDP.
GDP is highest in Western European countries. However, happyScore in a considering number of them is similar to countries in Latin American and Caribbean, even though GDP in these latter regions is lower.
The variation in happiness levels within the same region is greatest among Western European countries, although they all fall into the highest GDP category.
🔍 Take a closer look at the graph and see if you can identify any additional trends.
Drawing Bubble Charts
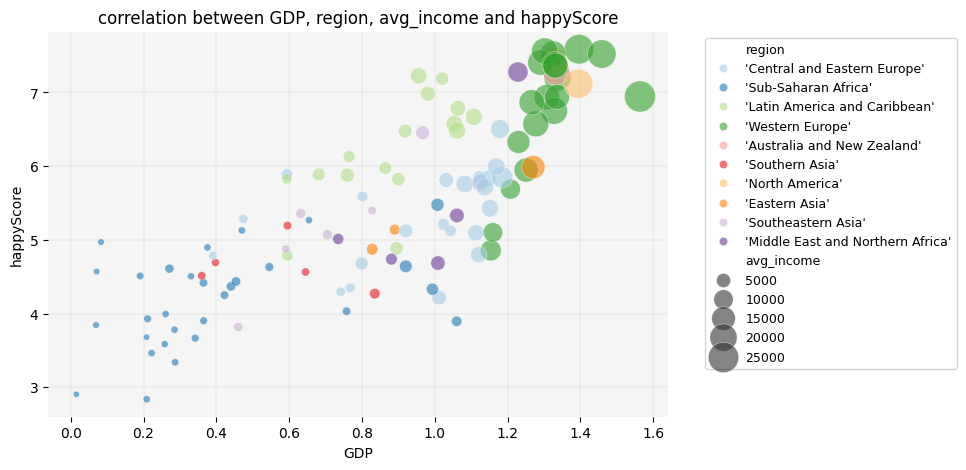
Let’s add one more variable to the graph to explore how avg_income is distributed across different regions and how it correlates with region, GDP and happyScore. We’ll add avg_income as the node size in the scatter plot, creating a bubble chart:
plt.figure(figsize=(8, 5))# adding avg_income to the graph as node size:sns.scatterplot(data=happy_df, x='GDP', y='happyScore', hue='region', size='avg_income', sizes=(20,500), palette='Paired', alpha=0.6, zorder=3)plt.grid(True, zorder=0, color='lightgray', linestyle='-', linewidth=0.3)sns.despine(left=True, bottom=True)plt.gca().set_facecolor('whitesmoke')plt.legend(fontsize='9', bbox_to_anchor=(1.05, 1), loc='upper left')plt.title('correlation between GDP, region, avg_income and happyScore')plt.show()
💡 Here, another interesting trend emerges: average income only begins to increase significantly once GDP exceeds a value of 1.
🔍 What additional insights can you derive from this graph? Consider exploring patterns such as which regions have high happyScore values relative to avg_income. You might also observe whether certain regions exhibit consistent patterns between avg_income and happyScore despite differences in GDP.
Diving Deeper into Details
As a final step in our exploration, let’s focus on the countries in Sub-Saharan Africa to identify which ones have a low GDP but a high happyScore:
# selecting only the countries that belong to the Sub-Saharan Africa and storing them in a new DataFrame:african_df= happy_df[happy_df['region']=="'Sub-Saharan Africa'"]african_df.head()
country
adjusted_satisfaction
avg_satisfaction
std_satisfaction
avg_income
median_income
income_inequality
region
happyScore
GDP
country.1
1
Angola
26.0
4.3
3.19
1448.88
1044.24
42.72
'Sub-Saharan Africa'
4.033
0.75778
Angola
8
Burkina Faso
37.0
4.4
2.02
870.84
630.24
39.76
'Sub-Saharan Africa'
3.587
0.25812
Burkina Faso
10
Burundi
25.0
2.9
1.96
572.88
436.92
33.36
'Sub-Saharan Africa'
2.905
0.01530
Burundi
11
Benin
20.0
3.0
2.70
989.04
657.00
43.44
'Sub-Saharan Africa'
3.340
0.28665
Benin
14
Botswana
36.0
4.7
2.42
3484.68
1632.60
60.46
'Sub-Saharan Africa'
4.332
0.99355
Botswana
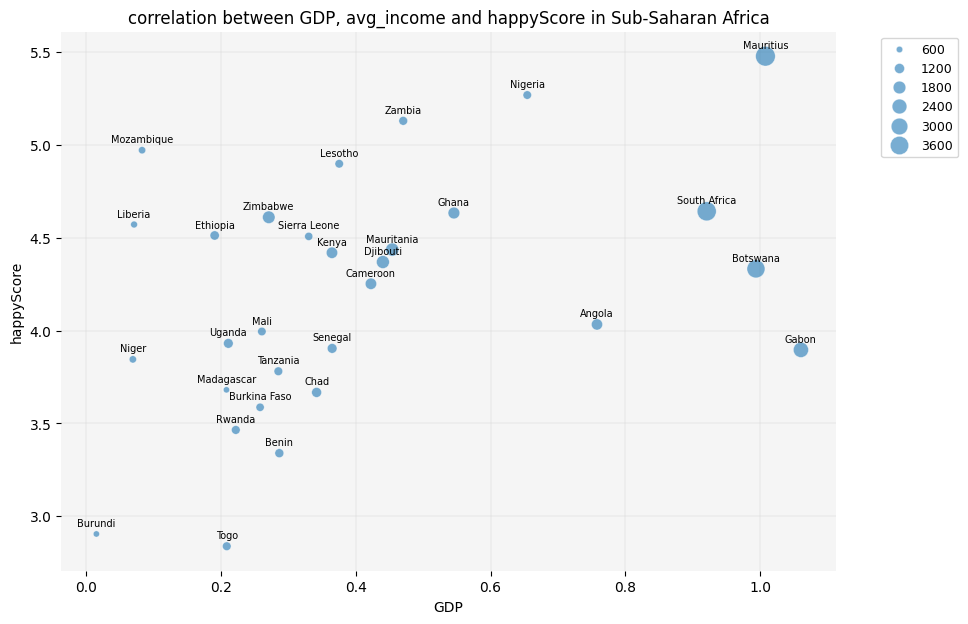
plt.figure(figsize=(10, 7))sns.scatterplot(data=african_df, x='GDP', y='happyScore', size='avg_income', sizes=(20, 200), alpha=0.6, zorder=3)plt.grid(True, zorder=0, color='lightgray', linestyle='-', linewidth=0.3)sns.despine(left=True, bottom=True)plt.gca().set_facecolor('whitesmoke')# adding country names to the nodes:for i inrange(len(african_df)): plt.text( african_df['GDP'].iloc[i], african_df['happyScore'].iloc[i]+0.03, african_df['country'].iloc[i], fontsize=7, ha='center', va='bottom' )plt.legend(fontsize='9', bbox_to_anchor=(1.05, 1), loc='upper left')plt.title('correlation between GDP, avg_income and happyScore in Sub-Saharan Africa')plt.show()
🔍 Let’s examine this scatter plot and compare it with the heatmap we created earlier:
The scatter plot reveals that some economically poor countries in Sub-Saharan Africa, such as Mozambique and Liberia, have a low GDP and avg-income but still demonstrate a high happyScore.
❓ But didn’t the heatmap show a positive correlation between happiness and GDP? Isn’t this a contradiction?!
✅ Yes and no! Remember, we excluded categorical data, such as region and country names, from happy_df to create the heatmap. By analyzing only numerical values, we observed a generally positive correlation between GDP and happyScore. However, the scatter plots and bubble chart suggest that cultural factors specific to each country significantly influence happiness. This impact is especially visible among Sub-Saharan African countries.
💡 Therefore, if we want to draw an inferential conclusion from our observations, it would be this: happiness appears to be influenced by a combination of GDP, income, and cultural factors. To predict a country’s happyScore based on our findings, we would need to know its region (which reflects GDP and cultural context) and possibly the country’s average income level.
Exercise
Take two countries that are not listed in the DataFrame, for example Iran and Turkey. Given the correlations that we have so far inferred from the dataset, try to predict how high their happyScore is. To do so, you need the following information:
Which region do these countries belong to? Which countries in happy_dfare culturally more similar to Iran and Turkey?
How high are GDP and avg_income in these countries?
look at the scatter plot with a regression line and the bubble chart and try to predict where these two countreies, Iran and Turkey, would be placed on the chart.
Conclusion
This lesson demonstrated how data visualization can teach the mathematical concepts behind machine learning and how it can be used not only to describe data but also to make preliminary predictions. While predictions based on visualization aren’t as precise as those derived through mathematical modeling, they can still support effective data storytelling.
In this lesson, you explored the concepts of statistical inference and regression through data visualization—two foundational processes in machine learning models. While we didn’t delve deeply into the mathematical details of these concepts, you learned their underlying logic and applied it by predicting the happyScore for two countries not included in the dataset. Additionally, you gained experience in visualizing scatter plots, bubble charts, and heatmaps using Python’s Seaborn library.
Understanding the difference between inferential and descriptive statistics, as introduced in this lesson, not only clarifies how machine learning models predict values but also strengthens your data storytelling skills. If you’ve primarily focused on describing existing data in your storytelling, you can now make approximate predictions for values not yet in your dataset based on the available data.
What’s Next?
Your next step could involve diving into the mathematical foundations of inferential statistics, including probability distributions, sampling methods, and the central limit theorem, to deepen your understanding of predictive models. You might also explore fundamental machine learning concepts, such as training and testing datasets and algorithms like linear regression and decision trees. Enhancing your Python data visualization skills and refining your approach to data storytelling by combining description and prediction could also be valuable next steps.