Challenge the Newspaper Data!
Informationen über die Challenge. Ggf. folgenden Auschreibungstext anpassen?
Das HERMES Datenkompetenzzentrum lädt euch ein, an unserer ersten Data Challenge teilzunehmen und die Zukunft der Digitalen Geisteswissenschaften mitzugestalten. Wir fordern euch heraus, die digitale Sammlung des Deutschen Zeitungsportals auf kritische und innovative Weise zu durchdringen und die Herausforderungen der Digitalisierung des kulturellen Erbes zu bewältigen. Bringt eure kritischen Denkweisen und eure datenwissenschaftlichen Fähigkeiten ein und zeigt, wie die Synthese von Geistes- und Datenwissenschaft zu bahnbrechenden Methoden und Lösungen im Bereich der Digital Humanities führen kann.
Woher stammt das Challenge-Konzept?
Die Digitalisierung von GLAM-Beständen (Galleries, Libraries, Archives und Museums) ist eine großartige Entwicklung, die ungeahnte Möglichkeiten eröffnet, das kulturelle Erbe zu erkunden und zu bewahren. Doch hinter den digitalen Kulissen verbirgt sich eine Welt voller Herausforderungen und ungelöster Fragen. Der digitale Bestand des Deutschen Zeitungsportals, den wir in unserer ersten Data Challenge behandeln, bildet hier keine Ausnahme.
Geistes- und Datenwissenschaftler_innen dürfen sich auf eine umfangreiche Sammlung digitalisierter Zeitungsdaten freuen. Sofort können sie sich in für ihre Fachdisziplin relevante und spannende Forschungsfragen vertiefen:
- In welcher Frequenz und welchem Kontext tauchen bestimmte Personen oder Ereignisse in Zeitungsartikeln zu einer bestimmten Zeit (nicht) auf? Was sagt das über die politische Haltung unterschiedlicher Zeitungen aus?
- Wie unterscheiden sich die Berichterstattungen verschiedener Zeitungen über dasselbe Ereignis in Ton und Umfang? Lassen sich lang- und kurzfristige Diskurse rekonstruieren, etwa zu Politik, Gesellschaft oder Kultur?
- In welchen Jahren steigt oder sinkt die Zahl der veröffentlichten Zeitungen und warum?
- An welchen Orten wurden die meisten Zeitungen in einem gewissen Zeitraum veröffentlicht? Welche politische und kulturelle Bedeutung hat das?
- Wie haben sich die Themenzusammensetzungen und Schwerpunkte der Zeitungen im Laufe der Zeit verändert? Welche Kolumnen sind hinzugekommen oder verschwunden? Und was sagt das über die Kommunikationsweise des Massenmediums Zeitung aus?
Aus Sicht einer historischen Data Science sind digitalisierte Zeitungsbestände ein ungehobener Schatz, weil sie potenziell Antworten auf diese und ähnliche Fragen bieten können. Der Umgang mit solchen Daten erfordert sowohl Teamwork als auch Vielfalt der Ideen und Disziplinen. Deshalb laden wir Euch ein, euch in diese Data Challenge einzubringen und gemeinsam die verborgenen Schätze dieser historischen Quellen zu entdecken.
Welche Daten werdet ihr erkunden?
Das Deutsche Zeitungsportal ist ein Sub-Portal der Deutschen Digitalen Bibliothek (DDB), welches Zeitungsbestände und -sammlungen von Kultur- und Wissenseinrichtungen zentral bereitstellt. Diese Datenpartner haben Zeitungen aus ihren Archiven gescannt, sie mittels OCR verarbeitet und der DDB zur Verfügung gestellt, um über das Zeitungsportal veröffentlicht zu werden.
Über die API des Deutschen Zeitungsportals haben wir sämtliche deutschsprachigen Zeitungsartikel und die dazugehörigen Metadaten aus den Jahren 1914-1945 heruntergeladen und in Pickled Pandas Data Frames gespeichert. Diese Daten (in Größe von 159 GB) stehen euch unter diesem Link zur Verfügung.
Was erwarten wir von euch?
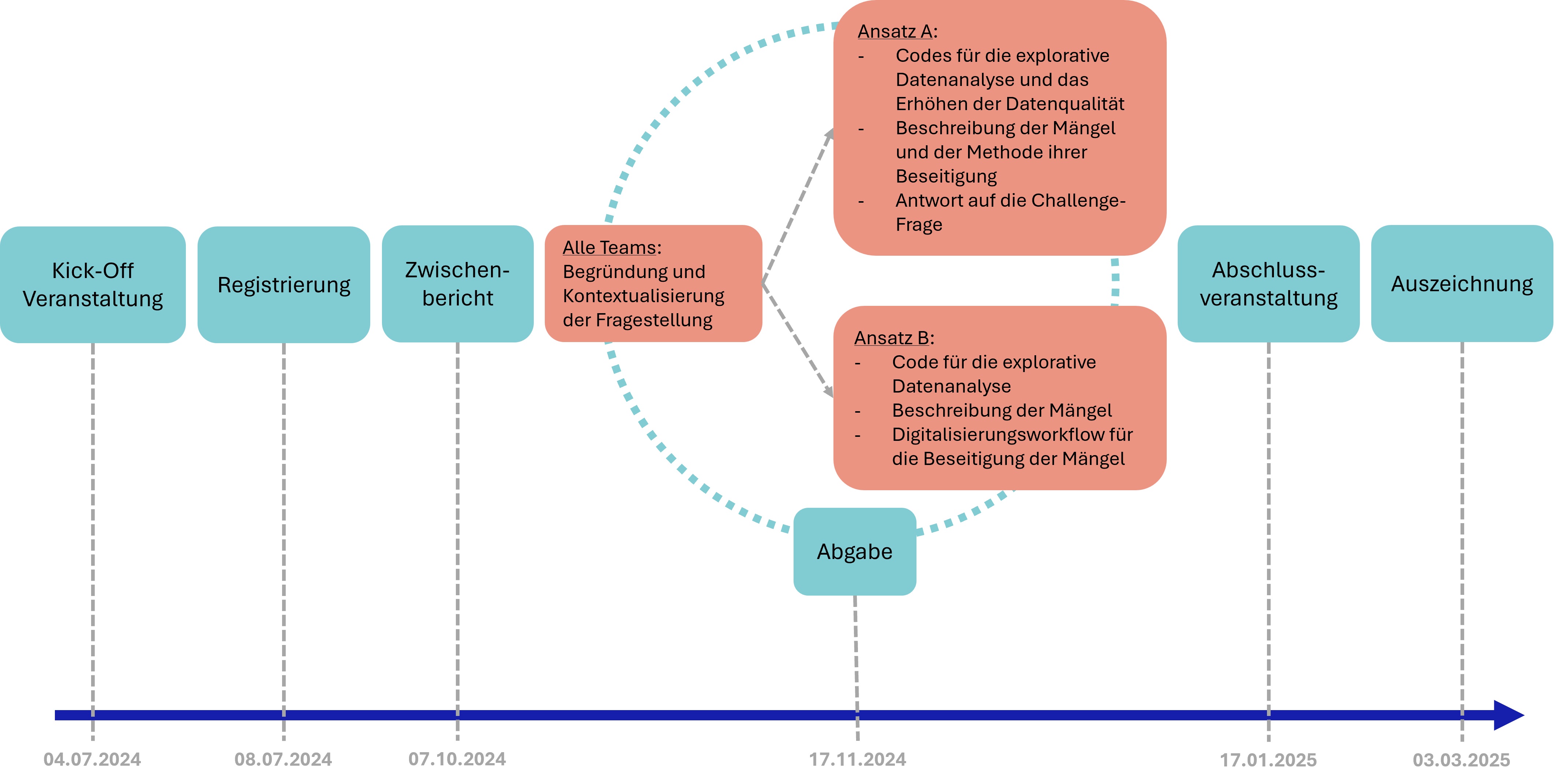
- Stellt eine für eure Fachrichtung relevante Frage an den Datensatz. Es wäre möglich, dass sich die Frage anhand der vorliegenden Daten (noch) nicht beantworten lässt. Diese Fragestellung ist jedoch trotzdem notwendig, um den Ansatz der explorativen Analyse im nächsten Schritt zu bestimmen.
Erste Abgabe für alle Teams: Begründung und Kontextualisierung der Fragestellung (PDF in DE oder EN, 200-300 Wörter).
Basierend auf eurer Fragestellung, analysiert den Datensatz explorativ und kritisch und stellt fest, ob er dafür geeignet ist, eine Antwort auf die gestellte Frage zu bieten. Von diesem Punkt an könnt ihr einen der folgenden Wege wählen:
Wenn euer Team in der Lage ist, die möglichen Mängel im Datensatz zwecks Beantwortung der gestellten Frage zu beseitigen, beseitigt diese Mängel anhand von datenwissenschaftlichen Methoden. Es kann z. B. sein, dass ihr die Volltexte der Zeitungsartikel und die dazugehörigen Metadaten bereinigt, dabei Feature Engineering oder Datenaggregation durchführt, oder einfach eine Auswahl der Daten trefft, die für euch als aussagekräftig erscheint. Entscheidet euch für diejenige datenwissenschaftliche Methode, die die Qualität der Daten zur fachwissenschaftlich soliden Beantwortung der gestellten Frage erhöht. Dann analysiert den verbesserten Datensatz und liefert dementsprechend eine fachwissenschaftliche Begründung für eure Antwort auf die ursprüngliche Frage.
Zweite Abgabe für Ansatz A: Die Codes (in Python, R oder Java), die für die explorative Datenanalyse und das Erhöhen der Datenqualität geschrieben wurden, in einem Jupyter Notebook; Beschreibung der Mängel und der Methode ihrer Beseitigung (PDF in DE oder EN, 300-500 Wörter); Antwort auf die Challenge-Frage (PDF in DE oder EN, 300-600 Wörter).Wenn ihr Mängel in dem Datensatz feststellt, deren Beseitigen dem Team grundsätzlich oder aufgrund der begrenzten Challengelaufzeit unmöglich erscheint, entwickelt einen (oder die Skizze eines) Workflow für die Mitgliedsbibliotheken der Deutschen Digitalen Bibliothek. Dieser Workflow soll sämtliche Schritte von der Auswahl der zu digitalisierenden Zeitungen bis hin zum Veröffentlichen der Digitalisate und der Informationen über ihren aktuellen Stand umfassen. Er soll den Bibliotheken dabei helfen, ihren Bestand in der Zukunft so zu digitalisieren und zu veröffentlichen, dass er sich für die Forschung in eurem Fachbereich besser eignet.
Zweite Abgabe für Ansatz B: Der Code (in Python, R oder Java), der für die explorative Datenanalyse geschrieben wurde, in einem Jupyter Notebook; Beschreibung der Mängel und des Workflow für ihre Beseitigung (PDF in DE oder EN, 1000-1500 Wörter).
Welche sind die Bewertungskriterien?
- Eine kreative geisteswissenschaftliche Fragestellung, die die Analyse von Big Data begründet und voraussetzt.
- Eine kritische und facettenreiche Analyse des Datensatzes.
- Einsatz von kreativen und möglichst generalisierbaren datenwissenschaftlichen Methoden zur Identifizierung und Beseitigung von Mängeln im Datensatz.
- Für Ansatz A: Ein solides Argument für die fachwissenschaftliche Antwort auf die gestellte Frage.
- Für Ansatz B: Entwicklung eines effizienten Plans für das Digitalisierungsverfahren der Zeitungen, der den FAIR-Prinzipien entspricht.
Wer kann teilnehmen?
Menschen aus jedem Fachbereich oder jeder Einrichtung, in denen die Veröffentlichungsmuster oder die Kommunikationsthemen der Zeitungen relevant sind, sind dazu ermutigt, an der Challenge teilzunehmen. Zudem sind Digital Humanists und Expert:innen aus den Bereichen Datenwissenschaft, Statistik und Programmieren herzlich eingeladen, die Geisteswissenschaftler:innen und GLAM-Mitarbeiter:innen mit ihrer Expertise zu unterstützen oder sogar individuell teilzunehmen.
Wenn du dich gern einem Team anschließen möchtest und noch auf der Suche nach Mitstreiter:innen bist, solltest du unbedingt an der Kick-Off-Veranstaltung der Challenge teilnehmen. Diese Veranstaltung dient vor allem dazu, dass Menschen aus verschiedenen Fachdisziplinen einander kennenlernen und Teams bilden können. Es ist aber auch möglich, dass du allein an der Challenge teilnimmst.
Wie ist der Challenge-Verlauf?
- Kick-Off-Veranstaltung: 04. Juli 2024, 16 Uhr (c.t.)
- Diese Veranstaltung findet online per Zoom auf Deutsch statt. Auf der Veranstaltung wird das Team des Datenkompetenzzentrums HERMES sich und das Challenge-Thema vorstellen. Darauf folgt eine Q&A Runde statt, in der die Fragen der Interessierten beantwortet werden. Schließlich lernen sich die Interessierten in Breakout-Rooms näher kennen und besprechen die Möglichkeiten einer Teambildung.
- Registrierung: 08. Juli 2024, bis 23:59 Uhr. Bitte nutzt den Anmeldung-Button unten, um euer Team für die Data Challenge zu registrieren.
- Zwischenberichtsveranstaltung: 07. Oktober 2024, 16 Uhr (c.t.) per Zoom
- Abgabe: 17. November 2024, bis 23:59 Uhr
- Jedes Team muss insgesamt ein Jupyter Notebook mit dem Titel “
_code.ipynb” und eine PDF-Datei mit dem Titel “ _text.pdf” abgeben. Bitte sendet beide Dateien per E-Mail an hermes.challenges@uni-marburg.de mit dem Teamnamen im Betreff. - Abschlussveranstaltung und Bekanntgabe des Siegers: 17. Januar 2025, 16 Uhr (c.t.) per Zoom
- Auszeichnung der Sieger: 03. März 2025. Das Projekt des Siegerteams wird von den Teammitgliedern auf der DHd-Tagung 2025 in Bielefeld vorgestellt. Weitere Details dazu werden bald bekanntgegeben.
Ihr könnt alle Entwicklungen rund um die Challenge über unseren Slack-Channel verfolgen. Bei Fragen schreibt jederzeit gerne eine Nachricht an das HERMES Team in Slack oder eine E-Mail an hermes.challenges@uni-marburg.de.
Neuigkeiten über die Challenge
Kacheln mit News, Blogbeiträgen und Events mit dem Tag “Challenge the Newspaper Data!”?